
| 导读 |
聚焦决策智能研究最新进展,促进前沿技术的应用落地。6月18日,第二届智能决策论坛正式召开,吸引超十万人次线上实时观看互动!论坛邀请了多位领域知名学者做学术报告并开展圆桌讨论,分享决策智能领域研究与应用的前沿成果。本系列文章将对嘉宾带来的精彩报告进行回顾梳理,欢迎各位读者一同讨论交流!
05 《从离线强化学习到决策大模型》张伟楠 上海交通大学 副教授
张伟楠副教授为我们带来题为《从离线强化学习到决策大模型》的报告。
报告第一部分介绍了离线强化学习(Offline RL)的基本概况。强化学习的训练可以基本分为三个范式,在线(online)强化学习,离策略(off policy)的强化学习以及离线(offline)强化学习。off policy的强化学习与离线强化学习都通过从replay buffer中采样得到的数据来评估策略,但离线强化学习中的智能体不与环境交互,replay buffer中大量的数据来自于数据集而非智能体的策略与环境交互生成,这样可以利用大量离线数据来预训练一个强化学习模型并经验主义地评估策略对于一组数据的利用能力,同时,这样也使得离线强化学习更加适用于向真实世界中策略的迁移以及强化学习的落地应用;所以离线强化学习相较于传统的更倾向于理论研究的强化学习有着更加广阔的应用范围。
在介绍了离线强化学习的优势与意义后,报告介绍了离线强化学习的一个主要的应用困境,就是推断误差(extrapolation error),因为前面提到了离线强化学习的数据并非来自于智能体与真实环境交互,所以基于当前策略与基于数据集的状态-行为分布会有一些不匹配。对于这种情况,张伟楠教授讲解了一种BCQ离线强化学习算法来解决该问题。BCQ算法利用state-conditioned生成模型来提供智能体见过的动作(令策略和replay buffer更相关)。BCQ算法在提出的同时证明了在譬如tabular设定下,这样的batch-constrained条件是要从不完整的数据集中学到MDP无偏价值函数估计的必要条件。由于BCQ考虑了推断误差并能够降低其影响获得价值的无偏估计,因此可以从任意数据中学习,而非仅仅类似于模仿学习从接近最优策略中学习,所以很适合离线强化学习。报告还介绍了一些BCQ算法之后的离线强化学习的工作,譬如AWR算法,BAIL算法等。
随后,报告从颠倒强化学习(Upside down RL)开始,介绍了监督学习,序列化建模与强化学习的结合。Upside down RL是由LSTM的作者团队提出来的,这个方法不预测回报(reward),而是通过监督学习的方法把它们映射到行为上。传统的强化学习中动作价值函数Q function通过输入观测与行为输出动作价值,指导策略学习,而颠倒强化学习则是通过将观测与命令(如期望回报,期望的horizon等),输出行为。这样可以令智能体学会通过有限资源等达成一些期望的状态等。
在介绍了监督学习以及序列化建模在强化学习中的一个重要应用后,报告还介绍了两种大模型与强化学习的结合,分别是Decision Transformer和Trajectory Transformer。Transformer架构和大模型近些年来在CV以及NLP应用场景中获得了巨大的成功,所以在离线强化学习中,也有很多团队尝试了大模型的应用,比如Decision Transformer仅采用了相较于传统大模型中少得多的参数即实现了在大量强化学习任务中达到接近sota的效果。传统的强化学习问题或者算法通常可以通过MDP与TD learning的方式进行建模或者解决,但是这样并不适用于Transformer的架构,此时将强化学习的轨迹重新定义为状态、行为、return to go的形式可以解决这类问题。return to go不再是某个timestep的强化学习获得的奖励,而是在某一timestep后所有reward的加和。对于这样的轨迹,将其中的每个元素进行一次embedding,再加上对于顺序(每个timestep共享一个)的编码可以得到多个token,将这些token通过Transformer进行处理后就得到了输出的token,随后对这些token进行解码获得对应的行为。这样结合较小规模的GPT模型,同时将强化学习问题重建为一个序列预测问题,就实现了Transformer在强化学习中的应用,为离线强化学习的未来发展提出了一个方向。张伟楠教授也展示了团队在决策大模型中的探索与尝试。
接下来,报告简单介绍了DeepMind近期的工作Gato。Gato也是Deepmind近期对于决策大模型的一个尝试,Gato将强化学习、计算机视觉和自然语言处理这三个领域的知识合到一起,实现了通过同一个模型完成多模态下的多任务并取得较好的效果。同时,报告也介绍了一些多智能体强化学习中的决策大模型应用。在讲座的最后,张伟楠副教授回顾了整场讲座并说明了对于决策大模型的总结与展望:决策大模型是智能体决策方面的一个重要研究,如今的决策大模型研究热点之一是利用大量数据,利用大模型以及离线强化学习训练来解决复杂、序列化的模式以及大量复合误差的问题;而未来可行的一些其他的研究方向是实现更好的环境建模、更高效的训练目标的表征、零样本迁移乃至多智能体的决策大模型应用等等。
来自中山大学计算机学院的余超副教授介绍了面向复杂多智能体系统的强化学习研究进展。
报告首先介绍了多智能体系统的三大特性:高动态性、大规模特性、非完全信息性,并进一步展开讨论。
报告中,余超副教授对于动态性求解方法,大规模智能体系统,非完全信息博弈以及强化学习的策略评估这四个方面进行了阐述,对于目前这四个领域的主流框架以及算法进行了详尽的介绍和分析,并对这些框架和算法存在问题提出了自己的见解以及相应的改进算法,展示了在不同环境下改进算法与主流算法的性能对比。
● 动态性求解方法
报告介绍了目前广泛采用的算法框架CTDE框架,该框架可以分为基于值和基于策略的两大类.其中基于策略的算法有:COMA(反事实优势函数),MAPPO(基于中央化值函数的多智能体ppo)但这些方法依然存在着一些问题,如依旧还是在值层面协同,缺乏对联合策略性能保障等。余超团队提出的CoPPO(协同近端策略优化算法)通过在中央式训练的过程中自适应地动态调整各个智能体的更新步长,直接对智能体的策略学习进行协同,该算法的亮点是实现了动态信任分配,缓解之前静态信任分配算带来的问题。团队在正则博弈上验证了CoPPO,实验证明该方法优于COMA、MAPPO以及DOP。此外,CoPPO在星际争霸2上也有很好的表现。
● 大规模智能体系统
报告分别介绍了一致性行为涌现(Norm Emergence)和均值场强化学习(MF),指出大规模智能体系统的难点就在于智能体之间交互会随着群体规模呈指数型增长。
目前主流的MFVDN(基于值分解的MF强化学习方法)在粒子环境和大规模博弈对抗环境下的效果比较优秀,但存在复杂度高、协同性会随规模增加而下降等问题。为了解决这些问题,余超团队提出的HMF(分层均值场方法),该方法对智能体进行分组,组内维护一个均值,不同组均值中心之间进行交互,通过底层学习模块和顶层学习模块实现组内学习和分组交互。该方法在粒子环境、酒吧博弈等环境下表现优秀,但基于均值场的方法缺少划分邻域范围的有效机制,为了解决这个问题,团队提出HMF-IPC(基于信息和策略一致性的动态分组算法),该方法利用K-means动态分组,用KL散度进行约束个体策略的更新过程。
● 非完全信息博弈
报告通过石头剪刀布的例子介绍了非完全信息的博弈,并介绍了该领域的主要求解方法:CFR方法、FP方法和种群学习,并介绍了CFR方法和FP的相关性。
其中FP方法的延伸——NFSP方法被认为是首个解决非完全信息的端到端的强化学习算法。但在实际应用中NFSP也存在着三个主要问题:优化目标变,资源消耗高,求解效率低。为了解决上述问题,余超团队分别提出了NFSP-EBC(基于经验偏差修正的神经虚拟自博弈算法),NFSP-KD(基于策略蒸馏的NFSP算法)以及BFSP(信念虚拟自博弈算法),都取得了显著的改进效果。
● 强化学习的策略评估
报告介绍了目前主流的策略评估方法如Elo rating system, α-rank,并通过alphastar的例子介绍了非传递性博弈问题,以及策略熵、新颖性搜索、CDS等评估方法。但这些策略评估方法都存在着一些不足,为了解决这些不足,余老师团队提出了UDM(统一的多样性度量指标):通过同时增大核矩阵的特征根个数和值来促进多样性。UDM在alphastar等进行了验证,取得了非常不错的效果。
最后,余老师对整场报告进行回顾总结与答疑。
来自新加坡南洋理工的安波副教授介绍了最近十几年来大规模博弈技术的突破以及深度学习在求解大规模博弈问题上的进展。
报告首先介绍了解决大规模博弈问题的动机:AI的研究促使智能体以及智能体系统不断发展,从上世纪50-70年代的单智能体到80年代的合作为主的多智能系统再到1995年以后以竞争为主的多智能体系统,许多现实问题都是博弈问题,如选举、德州扑克、谷歌的关键词搜索等,博弈论的研究和发展是非常有必要的。而AI解决了过去基于算法求解的博弈问题,如计算机扑克、安全博弈、广告、拍卖等。

安波副教授介绍了最近在求解博弈问题上的一些工作,如基于自动机实现算法(playing games with machines)。之后,报告着重指出了2000年后,人们倾向于解决更复杂的博弈问题,如pairs数量更多、不确定性更高、博弈的规模更大、求得的解更复杂,而且考虑智能体非完全理性的结果。安波副教授基于quantal模型来模拟人的conter response,以解决智能体非完全理性这一问题。
报告展示了一个与警方合作的项目:警员相互合作,在罪犯逃出某一地点之前抓住罪犯,并以此为例引出了Team-Maxmin Equlibria这一安全博弈问题。传统基于算法的方法很难在策略空间,规模较大时求出问题的解,因此机器学习和深度学习将在这方面得到更多应用。

接下来,安波副教授介绍了传统博弈论和机器学习适合解决什么样的问题,并快速回顾了2021年来所做的一些工作:第一是CFR-MIX,CFR是博弈论过去20年来非常重要的一个思想,适合解决规模较小的问题,安波教授借鉴了多智能体强化学习的一些想法,对CFR进行改进,使得多智能体之间相互协作;第二是针对传统FSP Neural化的一些工作,引入了表征学习的思想,优化低效的模块,提升其鲁棒性;最后介绍了NSGZero,用来求解大规模安全博弈问题。
最后,报告总结了解决大规模博弈问题的未来:DL+GT,也就是深度学习与传统基于算法的博弈理论的结合,希望国内相关领域的研究人员在这个方向上做出更多尝试。

圆桌讨论
主题一:智能决策在电力中的应用
程健
中国科学院自动化研究所 研究员
中科南京人工智能创新研究院 常务副院长
首先,程健研究员介绍了中科南京智能创新研究院。该院围绕自动化所的科技发展规划,依托自动化所的理论和技术,着眼于关键技术突破和应用转化。其主要研究方向为决策智能和计算研发,围绕这两个方向为国家重点行业赋能;同时,该研究院也是中国科学院大学南京学院人工智能方向承办单位。
决策智能在游戏棋牌已经有比较大的成果,并且也为理论研究提供很好的应用场景,但是这些相对成熟的理论研究方法在实际研究中还存在诸多问题。在如疫情防控,国际贸易,国际争端等复杂开放场景,现有的理论方法是否还能使用,是否会有新的困难产生,都是需要进一步考虑的。正是由于决策智能应用的重要性与实施的困难性,Gartner将决策智能列为2022年十大重要战略趋势之一。
对于具体面临的挑战,程健研究员进行了如下分类:对复杂系统建模困难,搜索空间巨大造成计算困难,以及对决策方法的解释困难。决策智能理论方法落地挑战重重。在其它行业中,缺少像人工智能领域中的数量庞大的专业人士以及便捷的通用共享平台。在过去缺少深度学习通用框架的时候,人工编写一套深度学习算法是非常复杂的。但是当tensorflow,pytorch这样的平台框架出现之后,编写、测试深度学习算法都逐渐变得简单起来。基于这样的想法,研究院依托自动化所,正协力打造决策智能与计算基础设施平台,涵盖基础的工具、计算模块,提供任务规划、态势感知、决策评估、决策仿真、进化计算以及竞争分析等基础功能,将打造成为可评估、可推演、可解释的新型AI基础设施,为科研单位,应用行业提供基础设施支撑。
在打造这个平台的过程中,研究院也在电力行业进行了示范应用探索。电力行业近年来也在不断地加入智能决策的相关应用,如利用智能感知进行寻线,缺陷检测等。但是随着电力系统逐渐复杂,尤其是在新能源加入后,不稳定性大大增加,风、光发电方式的发电量不可控,远距离输电时故障诊断,新能源加入后的电网高效调度等问题都亟待解决。研究院从发电,输电,配电,调度的决策方面进行了一定的探索。
主题二:强化学习产业应用的一些关键条件
俞扬
南京大学 教授
俞扬教授团队也在关注强化学习落地遇到的问题。在介绍了强化学习于游戏领域中的瞩目成果后,俞扬教授总结了将强化学习应用到真实环境的一些要求:(1)强化学习是一个试错的学习过程,而真实环境要求决策总是成功的;同时在真实环境中数据一般是在不断变化的,算法要求能够不断适应这些变化;(2)理论上的研究大都是基于大量数据的决策模型,而实际场景的数据量都是很少的。需要注意的是数据量的衡量维度不是绝对数量,而是指具体做了多少种决策。比如在推荐系统中,虽然用户量可以很大,但是想得到所有推荐品类在用户上的反馈结果是不现实的;(3)业务上线前需要足够的离线评估,需要向实施方说明模型究竟能达到什么样的效果,具体会执行什么样的动作,会有什么样的结果预期;(4)强化学习还并不算普及,需要足够的知识支撑强化学习的应用。以上种种要求都将目光指向了对模拟器,或者说环境模型的高度需要。但是工业场景一般没有很好的模型可供参考。例如,Deepmind在一种 Tokamak装置控制算法论文中提到,算法需要足够物理仿真度的模型才能达到较好的效果;同时高效的数据,具有较快速度的小模型也是算法实施的关键。种种这些都与前文总结的观点不一而同。
在Deepmind Alpha Go大放异彩之后,强化学习在业界得到一定程度的普及,团队也收到了来自业内的需求。在推荐系统的落地应用中,团队发现模拟器并不好做,早期并没有得到应用方的认可。期间,团队也尝试过直接从数据中学习策略的方案,但效果不太理想。后来才确定了由数据到模拟器的技术路线,在验证后上线,达到了不错的效果。
从此前的探索和实践总结下来,目前的离线强化学习,就是希望从数据上得到更好的策略,但是整体应用过程不完整,需要上线前的验证,这给研究者带来很大的挑战:因为决策的验证和监督训练的验证不同,监督有数据独立同分布假设,但决策的验证数据可能在历史上从未见过,目前来看效果不算太好。可能构建模拟器才是更高效的方法。
由于目前主流的Model-free在落地方面的种种困难,团队选择了Model-based的发展路线。同时不仅仅部分使用模型(Model-assistant),更要完整使用模型(Fully Model-based)。团队目前正在研究完整模型的学习。
在混动汽车控制的例子中,发现传统监督模型有很大误差,而基于模型的方法可以较好拟合。同时在构建好模型后,可以结合其他约束对策略进行更精确的优化。并可以结合实验结果对策略进行解释。在工业控制的例子中,在系统模型完全未知的情况下,通过数据能够较好地还原控制过程。这些例子都说明从有限的历史数据中学习模型,可以更好地服务强化学习落地应用。
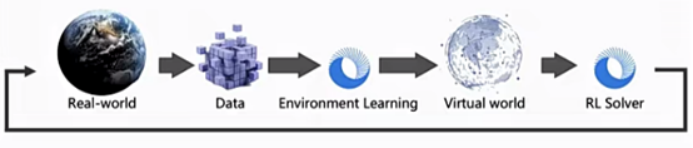
最后,俞扬教授对于为何应用落地如此重要的问题提出了一些思考。他指出,我们国内的科研要同国外同行竞争,而国外科研是为了其工业前沿服务的,我们在竞争中进入了别人的闭环,从而与国内业界脱节。希望未来国内也可以逐渐产生科研和工业的闭环。
主题三:基于黑盒优化的决策智能技术落地的挑战
郝建业
天津大学 副教授
华为诺亚方舟决策推理实验室 主任
郝建业副教授从黑盒优化的视角为我们介绍了决策智能落地的挑战。
黑盒优化技术是指通过黑盒优化方法,与黑盒系统进行尽可能少量的迭代交互,获得较好的策略模型。优化方法一般包括贝叶斯优化,启发式算法,以及现在热门的强化学习方法。目前,黑盒优化技术在游戏,互联网,推荐等虚拟场景已经展现了相当大的价值。同时,在真实物理场景中有诸多重要应用,如求解器优化、EDA工具优化、洗煤优化、车辆参数自标定、数据中心/园区节能优化、分布式计算机存储系统优化、天线设计优化、自动驾驶决策。
在求解器优化问题中,存在搜索空间大,参数间存在强耦合关系,评估函数存在突变,不光滑,奖励稀疏等问题,可以用超参优化方法解决。
在EDA领域中,报告举了三个例子:(1)DSE 设计空间搜索。用黑盒优化代替以往专家经验,寻找最优配置。存在着优化空间大,评估代价高,以及多目标的挑战;(2)DEA逻辑综合中里用黑盒优化选择面积优化算子,时延优化算子,以及超参数。存在搜索空间大,混合动作空间大,多目标,评估代价高的难点;(3)Macro Placement布局:给定连接关系,形状大小,布局区域等信息,给出所有macro到屋里位置的映射,从而优化整个不限过程的时间和线长模块多。存在搜索空间大、器件物理约束多、多目标的难点。
在洗煤优化中,可以里用黑盒优化方法,根据煤品质变化,为重介旋流器配置相关的参数取值。但是面临着模型中存在隐变量,函数不光滑,煤粒度等影响因素不可预测,多目标有约束,评估结果难以获得等诸多挑战。
在数据中心节能的例子中,里用黑盒优化可以控制关键控制变量,使得园区温度达到规定范围。同样存在着优化空间大,离线优化难,存在扰动等困难。
在计算机存储系统参数优化的例子中,利用黑盒优化学习控制超参,以达到减小延时,提高系统利用率的目的。无线天线优化中,黑盒优化可以自动设计透镜的形式,完成更好的功能。在无限多频段寻优的例子中,可以融合专家经验和多智能体学习,学习拓扑关系提升网络质量,实现更好的协同。
在实际应用之外,团队也很重视黑盒优化的打榜比赛,将对新的方法进行不断地探索。
转载自:https://mp.weixin.qq.com/s/n7y-r6WQlgv1s2Q3PiDFSg